
Hello again! Last time I gave y’all a little introduction on what are embeddings in Machine Learning. Today, we are going to go a bit deeper and talk about what is embedding in Natural Language Processing.
Embedding in Natural Language Processing
When we talk about embeddings in Natural Language Processing, the underlying technical process is very similar to what we had going on “general” Machine Learning problems. The difference is that this time, instead of representing shoes, or movies, or books, we are trying to represent words – and therefore, their associated concepts.
I think the best way to understand this is to visualize it, so I am going to show you a graph representing word embeddings in a three-dimensional space.
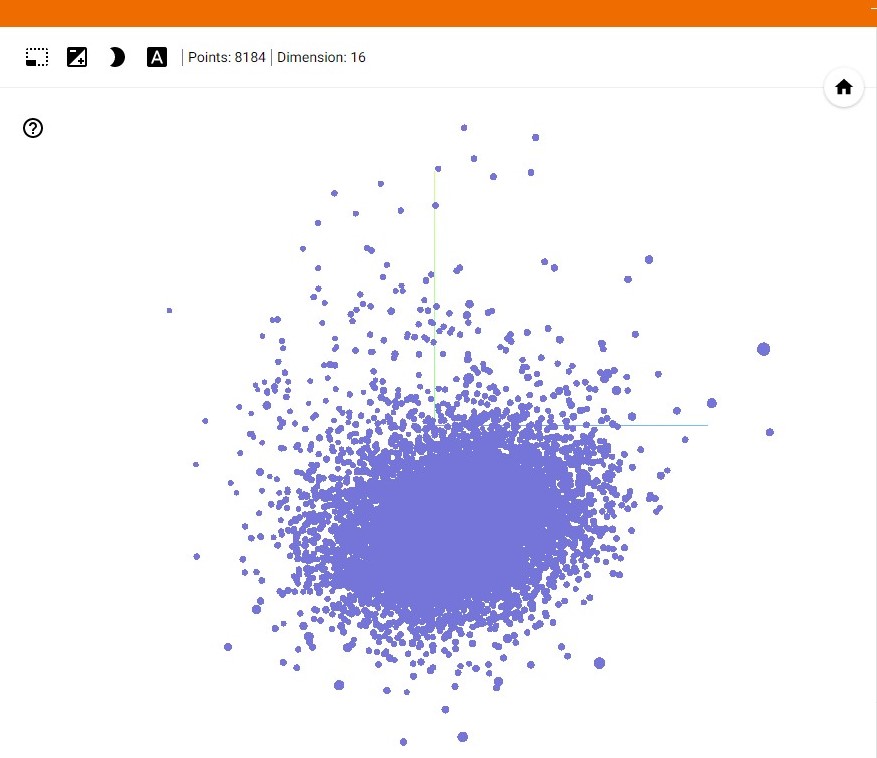
As you can see in the image, each word is represented as a dot in a three-dimensional space. This graph was generated from the embeddings of 25,000 IMDB movie reviews, and by using the Tensorboard Embedding Projector Plugin to visualize the data.
You can run the GoogleColab Notebook yourself and play around with it if you want. Just remember to pass
!pip install -q tfds-nightly
!tfds --version
in a cell to avoid any errors due to possible updates.
Now, this is all nice and well, but let’s be honest, it just looks like a bunch of random dots. So let’s try to zoom in on a specific word just a bit, to see why embeddings are so powerful in Natural Language Processing:
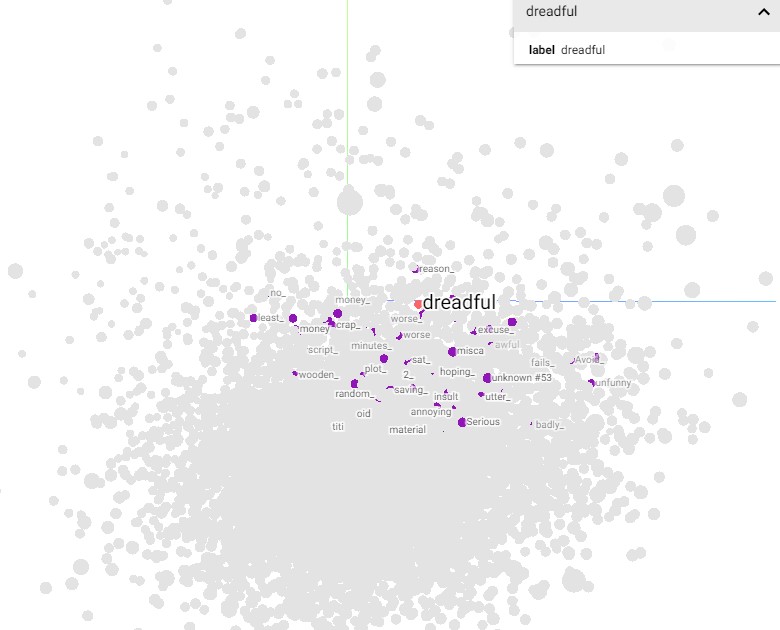
In the Tensorboard plugin, you can select one label (one word in our case), and see the neighboring labels. We selected “dreadful” as an example, and you can see some of the words in the proximity are “worse”, “random”, “annoying”, “insult”, “unfunny”…
All words you would use to describe a dreadful film! So what does this tell us about embeddings and language? As you might have guessed, embeddings representations of words tend to group together words with similar meaning. Think about it – unconsciously, this is exactly how we as humans represent language in our brain! We put together words that have a similar meaning or that are closely related (like family, love, affection) and we define opposites for those words as well, putting them in another subgroup.
Embeddings as a Representation of Language in Natural Language Processing
As we have seen, embeddings take a word and transform it into a vector that represents the word in an n-dimensional space (where n_dimension is the dimension of the embedding vector itself). We could say then that embeddings are nothing less than a representation of language, learned from the dataset. It is basically as if we were teaching our model how to speak – or better yet, understand – English, by letting the model see for itself which words are closely related.
What is even more interesting, is that the distance between two related concepts is often similar to the distance between two other concepts that have a similar relationship.
This concept can be a bit hard to grasp, so here is an example to make it easier:
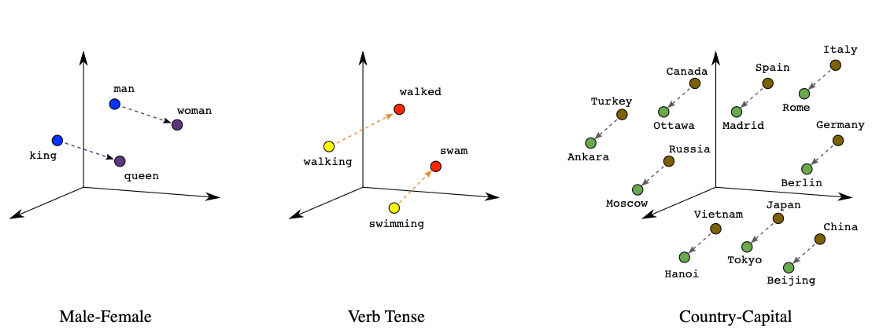
As you can see, the distance between woman and man is the same between king and queen – and for what matters, even the direction and inclination of the vectors are similar. The relationship between country and capitals is also represented by a similar distance.
Because the relationship between “king” and “queen” (male royalty – female royalty) is similar to the relationship between “man” and “woman” (male human – female human), we can perform mathematical operations on these concepts, and even define the famous equation: king – queen = man – woman.
When we talk about mathematical operations, we are actually talking about vector operations – we can subtract or add vectors to obtain “new” words or concepts.
Why Are Embeddings so Important in Natural Language Processing
As we have seen, the goal of this representation is to make words with similar meanings (semantically linked) have similar representations and be closer after arranging them in space. But why do we need all of this? Mainly for two reasons:
- Because computers cannot comprehend text or word relationships, you must express these words with numbers that computers can comprehend.
- Embeddings may be utilized in a variety of applications, including question answering systems, recommendation systems, sentiment analysis, text categorization, and making search and return synonyms simpler. Let’s look at an example to see how embeddings can help with all of this.
Embedding in Natural Language Processing Explained
See you in a bit!


